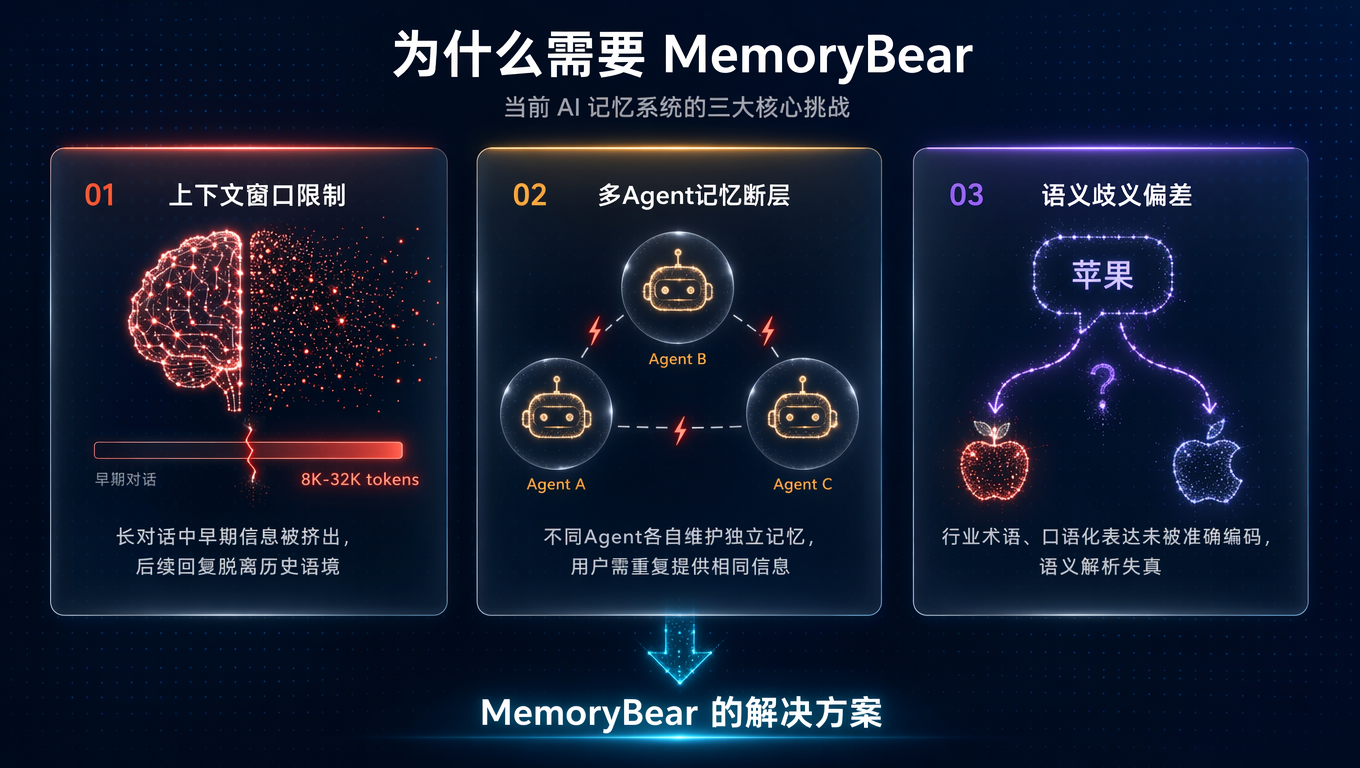
 ---
## 核心特性
---
## 核心特性
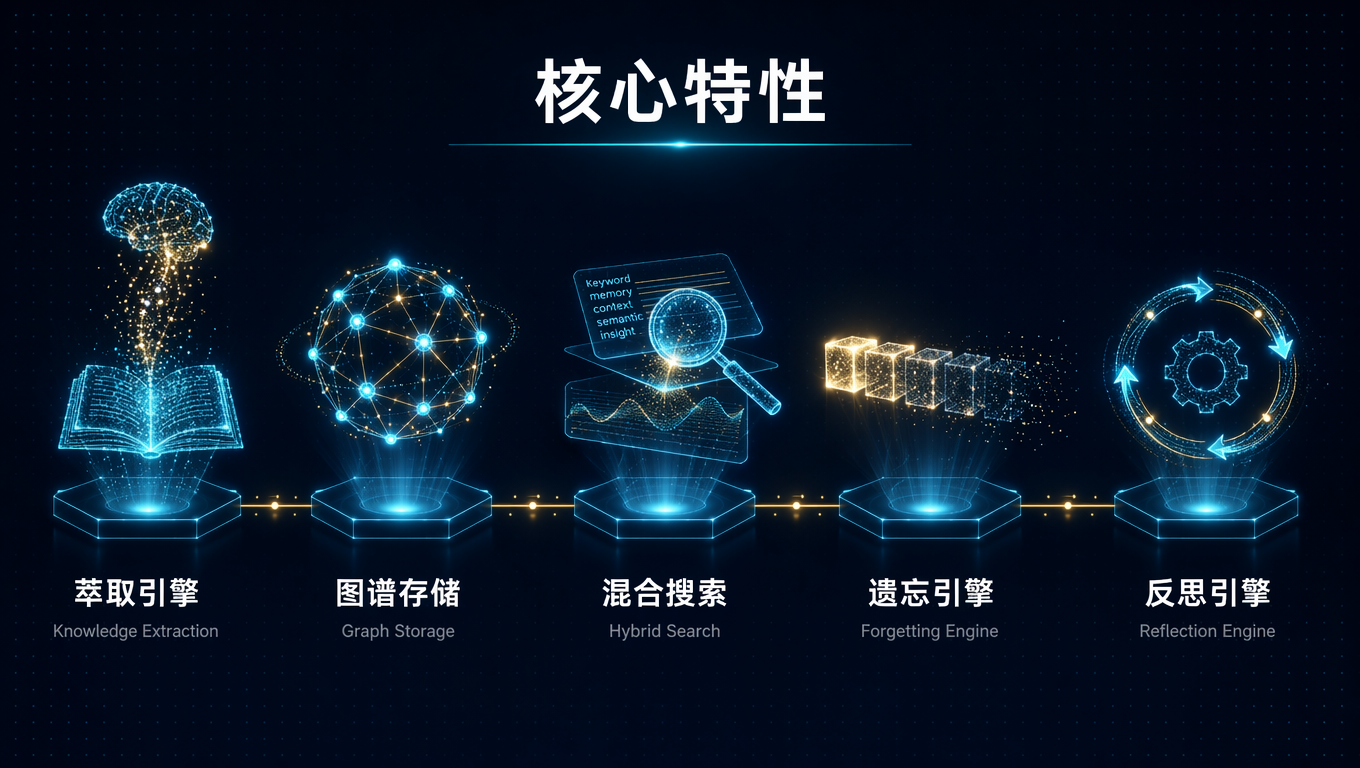 ### 记忆萃取引擎
从非结构化对话和文档中进行**语义级解析**,精准提取:
- **陈述句核心信息**:剥离冗余修饰,保留"主体-行为-对象"核心逻辑
- **三元组数据**:自动抽取实体关系(如 `MemoryBear → 核心功能 → 知识萃取`),为图谱存储提供基础数据单元
- **时序信息锚定**:自动提取并标记时间戳,支持时间维度的知识追溯
- **智能摘要生成**:支持自定义摘要长度(50–500 字)与侧重点,10 页技术文档 3 秒内生成精简摘要
### 图谱存储(Neo4j)
采用**图数据库优先**架构,对接 Neo4j,突破传统关系型数据库"关联弱、查询繁"的局限:
- 支持百万级知识实体及千万级关联关系
- 涵盖上下位、因果、时序、逻辑等 12 种核心关系类型
- 萃取的三元组直接同步至 Neo4j,自动构建初始知识图谱
- 支持图谱可视化交互,实现"机器构建 + 人工优化"协同管理
### 混合搜索
**关键词检索 + 语义向量检索**双引擎融合:
- 关键词检索基于 Elasticsearch,毫秒级精准定位结构化信息
- 语义向量检索通过 BERT 模型编码,识别同义词、近义词及隐含意图
- 先语义扩大候选范围,再关键词精准筛选,检索准确率达 **92%**,较单一方式提升 **35%**
### 记忆遗忘引擎
灵感源于生物大脑**突触修剪**机制,通过"记忆强度 + 时效"双维度模型实现知识动态衰减:
- 每条知识分配初始记忆强度,结合调用频率和关联活跃度实时更新
- 知识强度低于阈值后进入**休眠 → 衰减 → 清除**三阶段流程
- 系统冗余知识占比控制在 **8%** 以内,较无遗忘机制系统降低 **60%** 以上
### 自我反思引擎
每日定时触发自动反思流程,模拟人类"复盘总结"认知行为:
- **一致性校验**:检测关联知识间的逻辑冲突,标记可疑知识推送人工审核
- **价值评估**:统计调用频次和关联贡献度,高价值知识强化,低价值知识加速衰减
- **关联优化**:基于近期检索行为调整知识间关联权重,强化高频关联路径
### FastAPI 服务层
统一服务架构,暴露两套 API:
| API 类型 | 路径前缀 | 认证方式 | 用途 |
|----------|----------|----------|------|
| 管理端 API | `/api` | JWT | 系统配置、权限管理、日志查询 |
| 服务端 API | `/v1` | API Key | 知识萃取、图谱操作、搜索查询、遗忘控制 |
- 平均响应延迟低于 **50ms**,单实例支撑 **1000 QPS** 并发
- 自动生成 Swagger 文档,支持 Docker 容器化部署
- 兼容企业级微服务体系,可对接 CRM、OA、研发管理等业务系统
---
## 架构总览
### 记忆萃取引擎
从非结构化对话和文档中进行**语义级解析**,精准提取:
- **陈述句核心信息**:剥离冗余修饰,保留"主体-行为-对象"核心逻辑
- **三元组数据**:自动抽取实体关系(如 `MemoryBear → 核心功能 → 知识萃取`),为图谱存储提供基础数据单元
- **时序信息锚定**:自动提取并标记时间戳,支持时间维度的知识追溯
- **智能摘要生成**:支持自定义摘要长度(50–500 字)与侧重点,10 页技术文档 3 秒内生成精简摘要
### 图谱存储(Neo4j)
采用**图数据库优先**架构,对接 Neo4j,突破传统关系型数据库"关联弱、查询繁"的局限:
- 支持百万级知识实体及千万级关联关系
- 涵盖上下位、因果、时序、逻辑等 12 种核心关系类型
- 萃取的三元组直接同步至 Neo4j,自动构建初始知识图谱
- 支持图谱可视化交互,实现"机器构建 + 人工优化"协同管理
### 混合搜索
**关键词检索 + 语义向量检索**双引擎融合:
- 关键词检索基于 Elasticsearch,毫秒级精准定位结构化信息
- 语义向量检索通过 BERT 模型编码,识别同义词、近义词及隐含意图
- 先语义扩大候选范围,再关键词精准筛选,检索准确率达 **92%**,较单一方式提升 **35%**
### 记忆遗忘引擎
灵感源于生物大脑**突触修剪**机制,通过"记忆强度 + 时效"双维度模型实现知识动态衰减:
- 每条知识分配初始记忆强度,结合调用频率和关联活跃度实时更新
- 知识强度低于阈值后进入**休眠 → 衰减 → 清除**三阶段流程
- 系统冗余知识占比控制在 **8%** 以内,较无遗忘机制系统降低 **60%** 以上
### 自我反思引擎
每日定时触发自动反思流程,模拟人类"复盘总结"认知行为:
- **一致性校验**:检测关联知识间的逻辑冲突,标记可疑知识推送人工审核
- **价值评估**:统计调用频次和关联贡献度,高价值知识强化,低价值知识加速衰减
- **关联优化**:基于近期检索行为调整知识间关联权重,强化高频关联路径
### FastAPI 服务层
统一服务架构,暴露两套 API:
| API 类型 | 路径前缀 | 认证方式 | 用途 |
|----------|----------|----------|------|
| 管理端 API | `/api` | JWT | 系统配置、权限管理、日志查询 |
| 服务端 API | `/v1` | API Key | 知识萃取、图谱操作、搜索查询、遗忘控制 |
- 平均响应延迟低于 **50ms**,单实例支撑 **1000 QPS** 并发
- 自动生成 Swagger 文档,支持 Docker 容器化部署
- 兼容企业级微服务体系,可对接 CRM、OA、研发管理等业务系统
---
## 架构总览
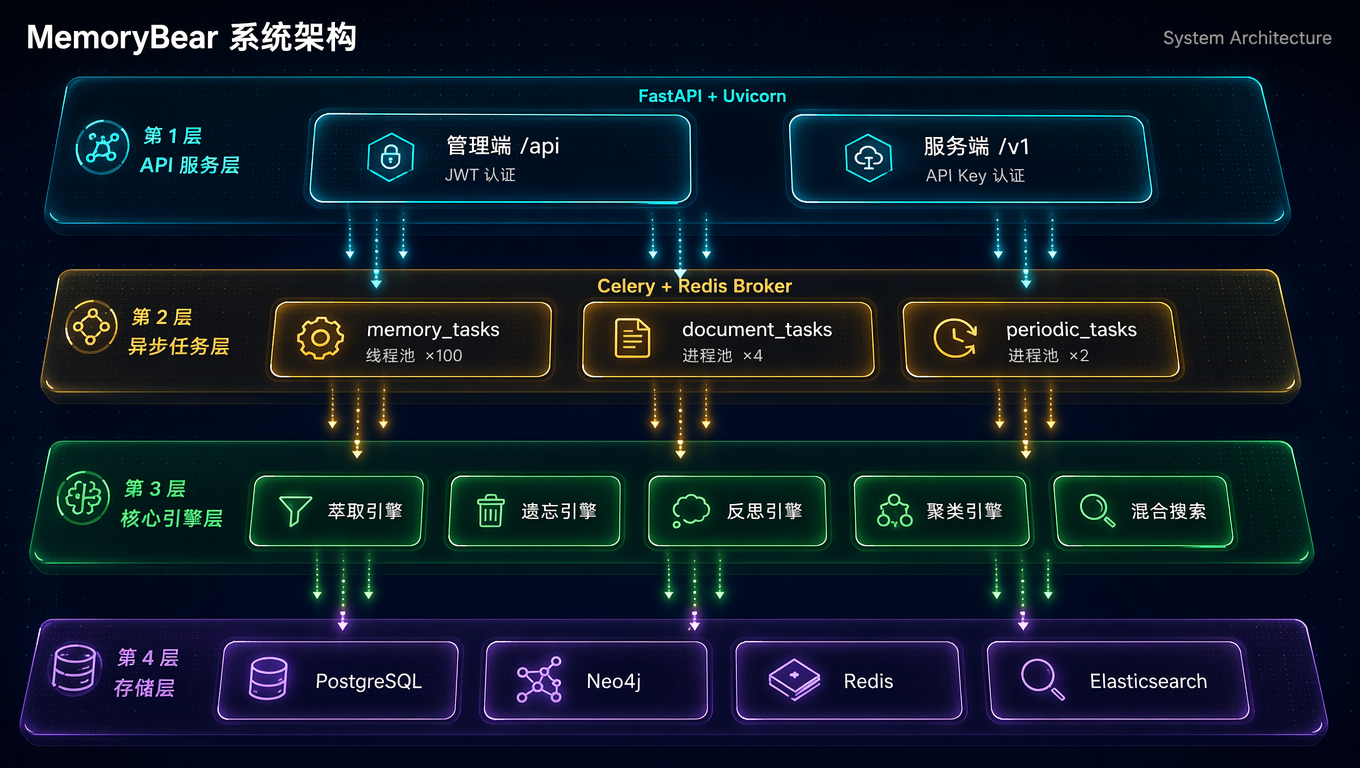 **Celery 三队列异步架构:**
| 队列 | Worker 类型 | 并发 | 用途 |
|------|-------------|------|------|
| `memory_tasks` | threads | 100 | 记忆读写(asyncio 友好) |
| `document_tasks` | prefork | 4 | 文档解析(CPU 密集) |
| `periodic_tasks` | prefork | 2 | 定时任务、反思引擎 |
---
## 实验室指标
评估指标包括 F1 分数(F1)、BLEU-1(B1)以及 LLM-as-a-Judge 分数(J),数值越高表示性能越好。
MemoryBear 在四大任务类型的核心指标中,均优于行业内竞争对手 Mem0、Zep、LangMem 等现有方法:
**Celery 三队列异步架构:**
| 队列 | Worker 类型 | 并发 | 用途 |
|------|-------------|------|------|
| `memory_tasks` | threads | 100 | 记忆读写(asyncio 友好) |
| `document_tasks` | prefork | 4 | 文档解析(CPU 密集) |
| `periodic_tasks` | prefork | 2 | 定时任务、反思引擎 |
---
## 实验室指标
评估指标包括 F1 分数(F1)、BLEU-1(B1)以及 LLM-as-a-Judge 分数(J),数值越高表示性能越好。
MemoryBear 在四大任务类型的核心指标中,均优于行业内竞争对手 Mem0、Zep、LangMem 等现有方法:
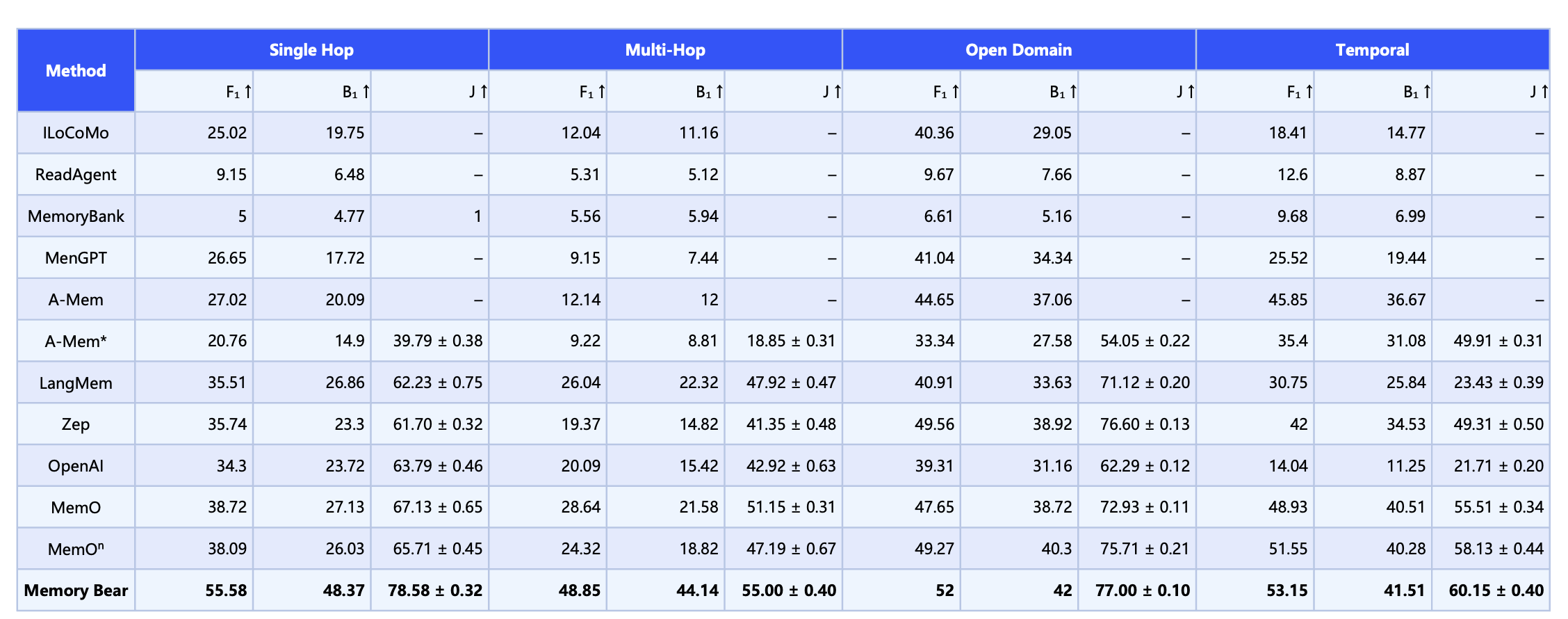 **向量版本(非图谱)**:在保持高准确性的同时极大优化了检索效率,总体准确性明显高于现有最高全文检索方法(72.90 ± 0.19%),且在 Search Latency 和 Total Latency 的 p50/p95 上保持较低水平。
**向量版本(非图谱)**:在保持高准确性的同时极大优化了检索效率,总体准确性明显高于现有最高全文检索方法(72.90 ± 0.19%),且在 Search Latency 和 Total Latency 的 p50/p95 上保持较低水平。
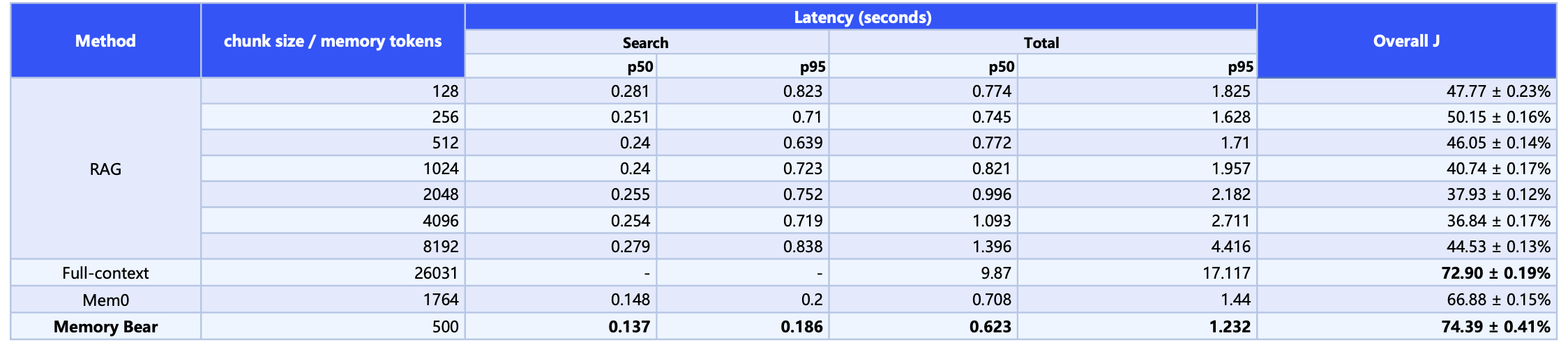 **图谱版本**:通过集成知识图谱架构,将总体准确性推至新高度(**75.00 ± 0.20%**),在保持准确性的同时整体指标显著优于所有其他方法。
**图谱版本**:通过集成知识图谱架构,将总体准确性推至新高度(**75.00 ± 0.20%**),在保持准确性的同时整体指标显著优于所有其他方法。
 ---
## 快速开始
### Docker Compose 一键启动(推荐)
**前提条件**:已安装 [Docker Desktop](https://www.docker.com/products/docker-desktop/)。
```bash
# 1. 克隆项目
git clone https://github.com/SuanmoSuanyangTechnology/MemoryBear.git
cd MemoryBear/api
# 2. 启动基础服务(PostgreSQL / Neo4j / Redis / Elasticsearch)
# 请先通过 Docker Desktop 拉取并启动以下镜像(详见安装教程 3.2 节)
# 3. 配置环境变量
cp env.example .env
# 编辑 .env,填写数据库连接信息和 LLM API Key
# 4. 初始化数据库
pip install uv && uv sync
alembic upgrade head
# 5. 启动 API + Celery Workers + Beat 调度器
docker-compose up -d
# 6. 初始化系统,获取超级管理员账号
curl -X POST http://127.0.0.1:8002/api/setup
```
> **注意**:`docker-compose.yml` 包含 API 服务和 Celery Workers,基础服务(PostgreSQL、Neo4j、Redis、Elasticsearch)需要单独启动。
>
> **端口说明**:Docker Compose 部署默认端口为 `8002`,手动启动默认端口为 `8000`。下文安装教程以手动启动(`8000`)为例。
服务启动后访问:
- API 文档:http://localhost:8002/docs
- 管理后台:http://localhost:3000(启动前端后)
**默认管理员账号:**
- 账号:`admin@example.com`
- 密码:`admin_password`
### 手动启动
> 以下为精简命令,详细步骤请参考 [安装教程](#安装教程)。
```bash
# 后端
cd api
pip install uv && uv sync
alembic upgrade head
uv run -m app.main
# 前端(新终端)
cd web
npm install && npm run dev
```
---
## 安装教程
### 一、环境要求
| 组件 | 版本要求 | 用途 |
|------|----------|------|
| Python | 3.12+ | 后端运行环境 |
| Node.js | 20.19+ 或 22.12+ | 前端运行环境 |
| PostgreSQL | 13+ | 主数据库 |
| Neo4j | 4.4+ | 知识图谱存储 |
| Redis | 6.0+ | 缓存与消息队列 |
| Elasticsearch | 8.x | 混合搜索引擎 |
### 二、项目获取
```bash
git clone https://github.com/SuanmoSuanyangTechnology/MemoryBear.git
```
---
## 快速开始
### Docker Compose 一键启动(推荐)
**前提条件**:已安装 [Docker Desktop](https://www.docker.com/products/docker-desktop/)。
```bash
# 1. 克隆项目
git clone https://github.com/SuanmoSuanyangTechnology/MemoryBear.git
cd MemoryBear/api
# 2. 启动基础服务(PostgreSQL / Neo4j / Redis / Elasticsearch)
# 请先通过 Docker Desktop 拉取并启动以下镜像(详见安装教程 3.2 节)
# 3. 配置环境变量
cp env.example .env
# 编辑 .env,填写数据库连接信息和 LLM API Key
# 4. 初始化数据库
pip install uv && uv sync
alembic upgrade head
# 5. 启动 API + Celery Workers + Beat 调度器
docker-compose up -d
# 6. 初始化系统,获取超级管理员账号
curl -X POST http://127.0.0.1:8002/api/setup
```
> **注意**:`docker-compose.yml` 包含 API 服务和 Celery Workers,基础服务(PostgreSQL、Neo4j、Redis、Elasticsearch)需要单独启动。
>
> **端口说明**:Docker Compose 部署默认端口为 `8002`,手动启动默认端口为 `8000`。下文安装教程以手动启动(`8000`)为例。
服务启动后访问:
- API 文档:http://localhost:8002/docs
- 管理后台:http://localhost:3000(启动前端后)
**默认管理员账号:**
- 账号:`admin@example.com`
- 密码:`admin_password`
### 手动启动
> 以下为精简命令,详细步骤请参考 [安装教程](#安装教程)。
```bash
# 后端
cd api
pip install uv && uv sync
alembic upgrade head
uv run -m app.main
# 前端(新终端)
cd web
npm install && npm run dev
```
---
## 安装教程
### 一、环境要求
| 组件 | 版本要求 | 用途 |
|------|----------|------|
| Python | 3.12+ | 后端运行环境 |
| Node.js | 20.19+ 或 22.12+ | 前端运行环境 |
| PostgreSQL | 13+ | 主数据库 |
| Neo4j | 4.4+ | 知识图谱存储 |
| Redis | 6.0+ | 缓存与消息队列 |
| Elasticsearch | 8.x | 混合搜索引擎 |
### 二、项目获取
```bash
git clone https://github.com/SuanmoSuanyangTechnology/MemoryBear.git
```
 ### 三、后端 API 服务启动
#### 3.1 安装 Python 依赖
```bash
# 安装依赖管理工具 uv
pip install uv
# 切换到 API 目录
cd api
# 安装依赖
uv sync
# 激活虚拟环境
# Windows (PowerShell,在 api 目录下)
.venv\Scripts\Activate.ps1
# Windows (cmd,在 api 目录下)
.venv\Scripts\activate.bat
# macOS / Linux
source .venv/bin/activate
```
#### 3.2 安装基础服务(Docker 镜像)
使用 Docker Desktop 安装所需镜像:[下载 Docker Desktop](https://www.docker.com/products/docker-desktop/)
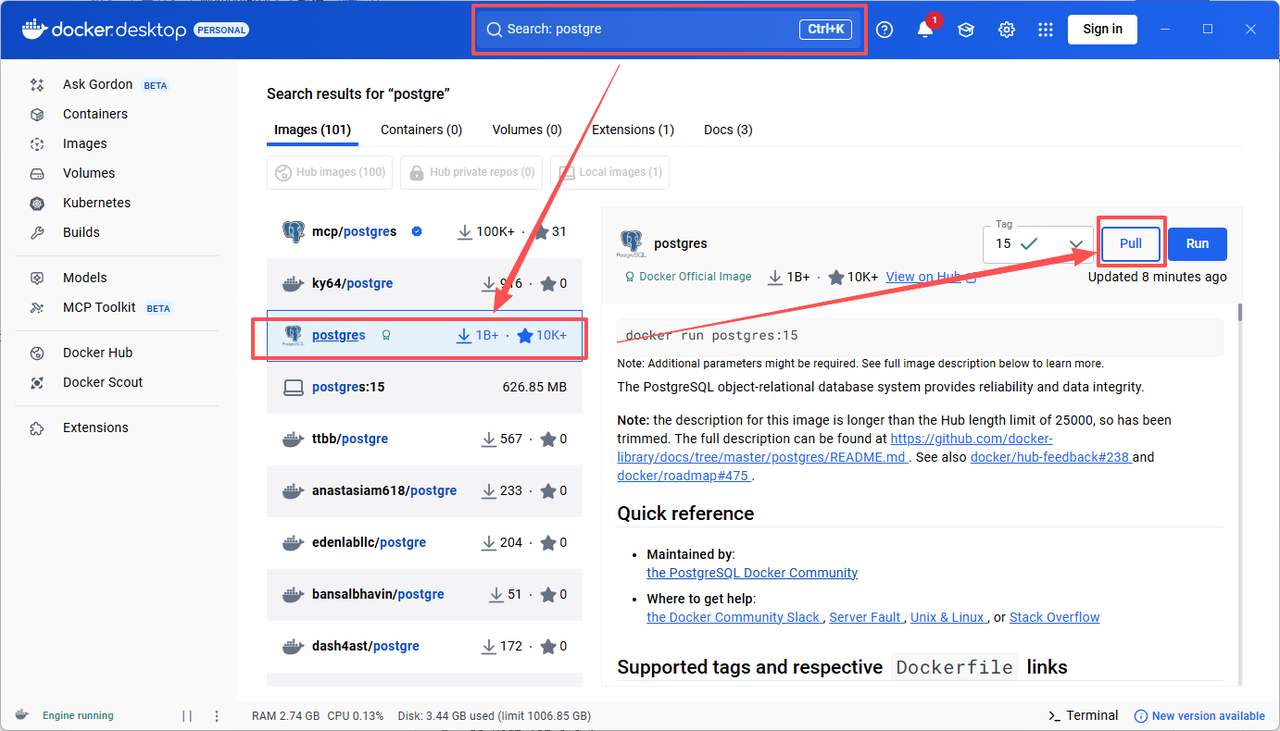
**PostgreSQL**
拉取镜像:search → select → pull
### 三、后端 API 服务启动
#### 3.1 安装 Python 依赖
```bash
# 安装依赖管理工具 uv
pip install uv
# 切换到 API 目录
cd api
# 安装依赖
uv sync
# 激活虚拟环境
# Windows (PowerShell,在 api 目录下)
.venv\Scripts\Activate.ps1
# Windows (cmd,在 api 目录下)
.venv\Scripts\activate.bat
# macOS / Linux
source .venv/bin/activate
```
#### 3.2 安装基础服务(Docker 镜像)
使用 Docker Desktop 安装所需镜像:[下载 Docker Desktop](https://www.docker.com/products/docker-desktop/)
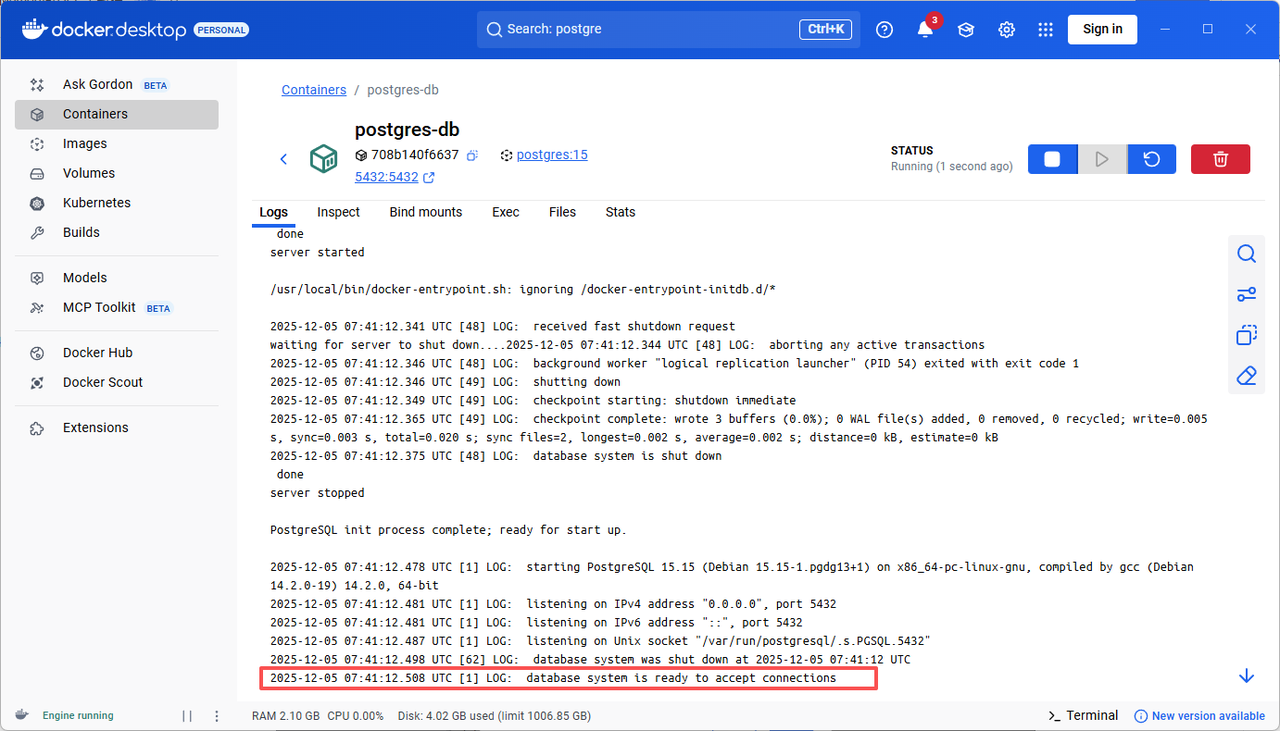
**PostgreSQL**
拉取镜像:search → select → pull
 创建容器:
创建容器:
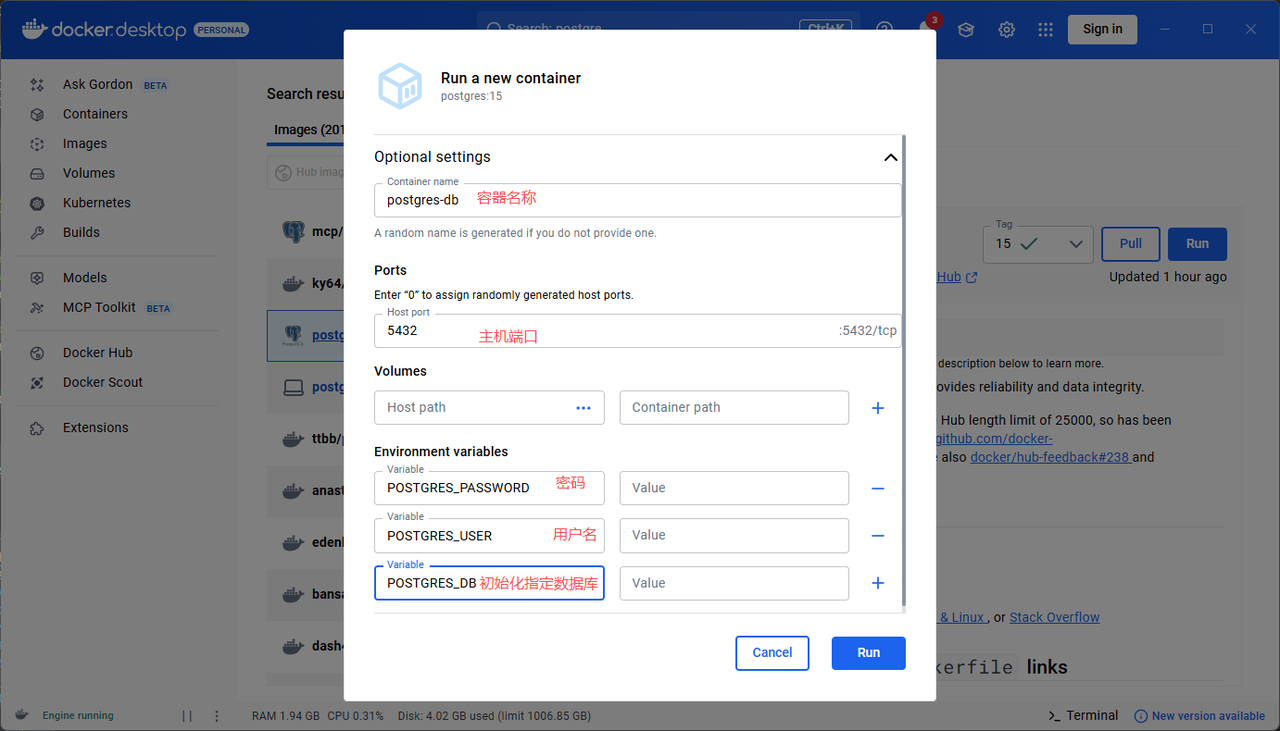
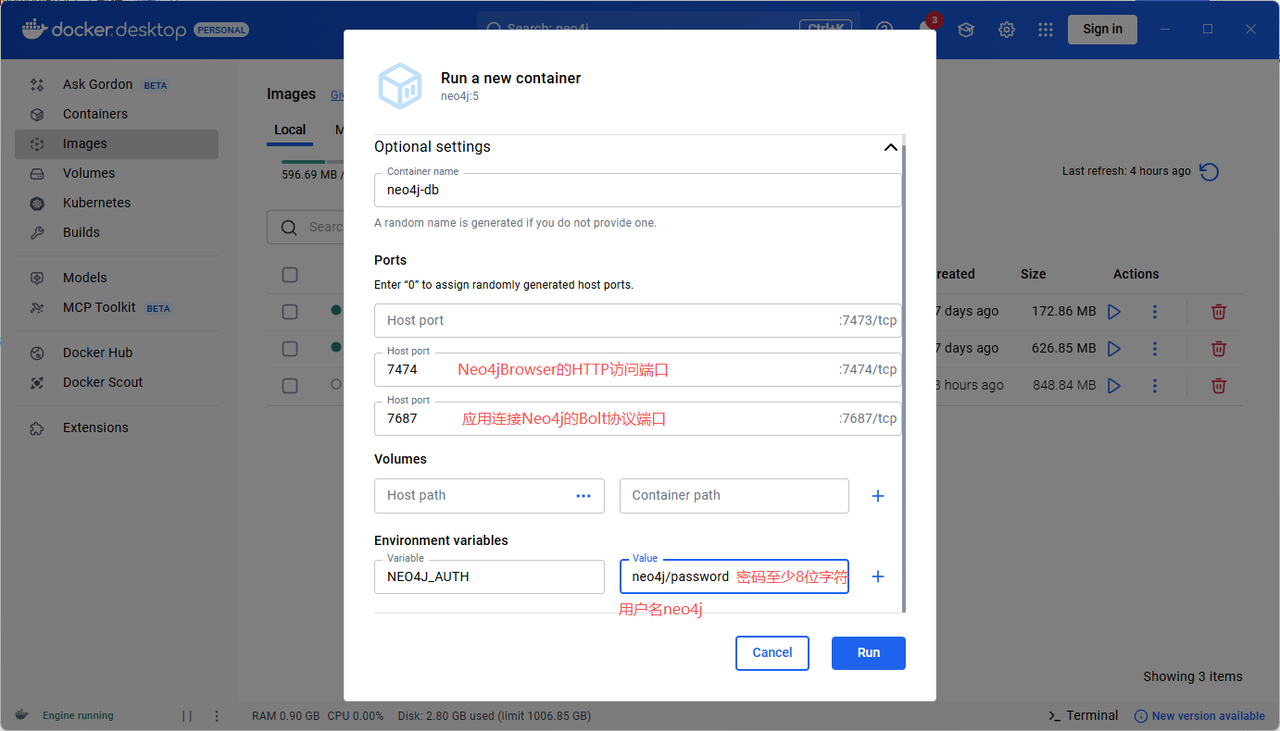
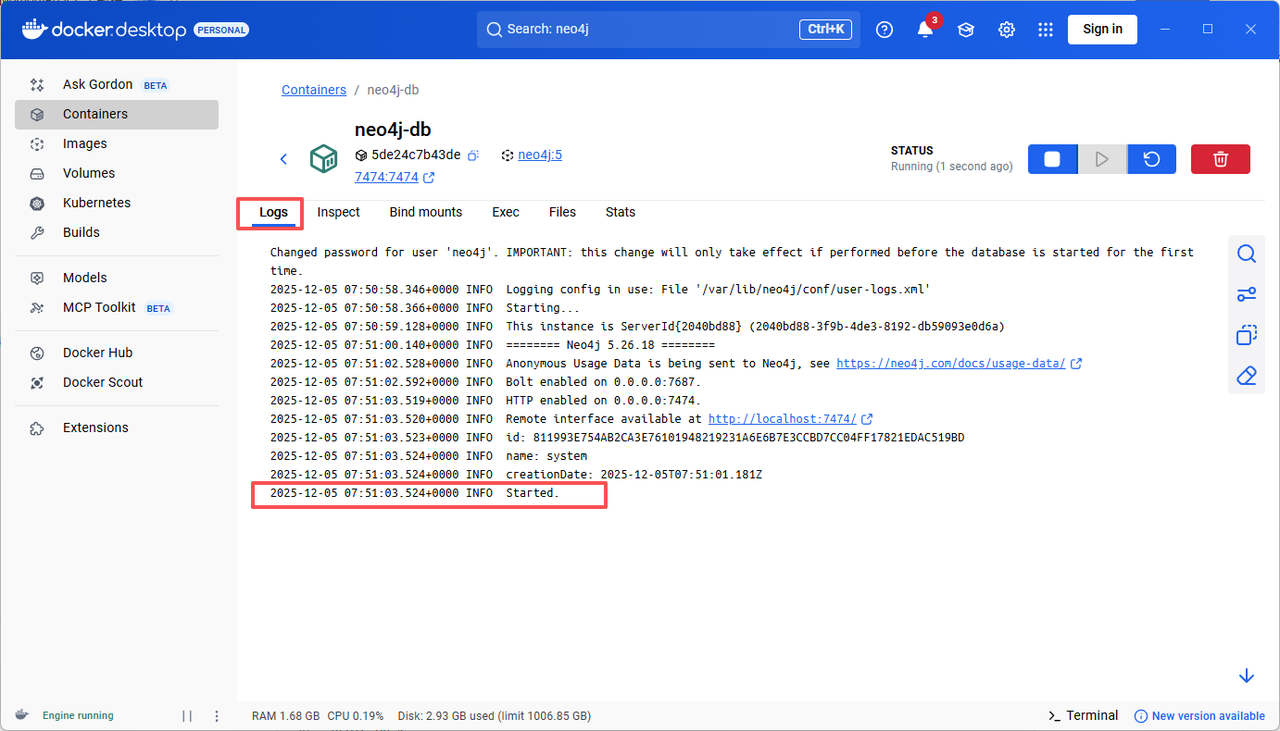
 **Neo4j**
拉取镜像方式同上。创建容器时需映射两个关键端口,并设置初始密码:
- `7474`:Neo4j Browser
- `7687`:Bolt 协议
**Neo4j**
拉取镜像方式同上。创建容器时需映射两个关键端口,并设置初始密码:
- `7474`:Neo4j Browser
- `7687`:Bolt 协议
 **Redis**:同上步骤拉取并创建容器。
**Elasticsearch**
拉取 Elasticsearch 8.x 镜像并创建容器,映射端口 `9200`(HTTP API)和 `9300`(集群通信)。首次启动建议关闭安全认证以简化配置:
```bash
docker run -d --name elasticsearch \
-p 9200:9200 -p 9300:9300 \
-e "discovery.type=single-node" \
-e "xpack.security.enabled=false" \
elasticsearch:8.15.0
```
#### 3.3 配置环境变量
```bash
cp env.example .env
```
编辑 `.env` 填写以下核心配置:
```bash
# Neo4j 图数据库
NEO4J_URI=bolt://localhost:7687
NEO4J_USERNAME=neo4j
NEO4J_PASSWORD=your-password
# PostgreSQL 数据库
DB_HOST=127.0.0.1
DB_PORT=5432
DB_USER=postgres
DB_PASSWORD=your-password
DB_NAME=redbear-mem
# 首次启动设为 true,自动迁移数据库
DB_AUTO_UPGRADE=true
# Redis
REDIS_HOST=127.0.0.1
REDIS_PORT=6379
REDIS_DB=1
# Celery
REDIS_DB_CELERY_BROKER=1
REDIS_DB_CELERY_BACKEND=2
# Elasticsearch
ELASTICSEARCH_HOST=127.0.0.1
ELASTICSEARCH_PORT=9200
# JWT 密钥(生成方式:openssl rand -hex 32)
SECRET_KEY=your-secret-key-here
```
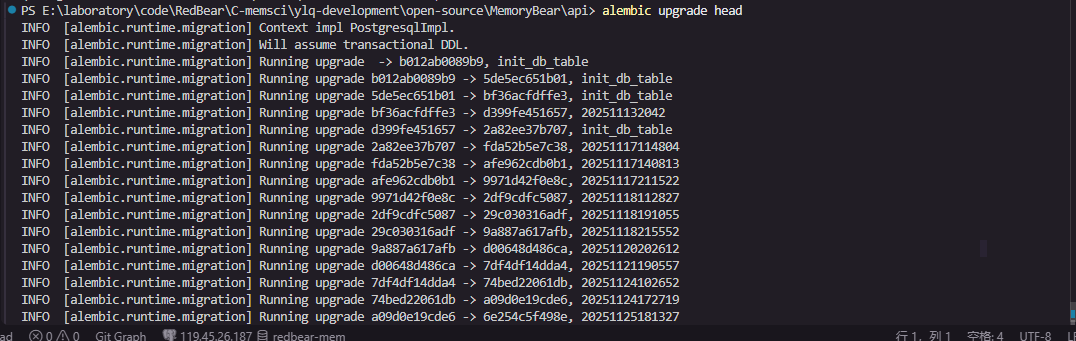
#### 3.4 初始化 PostgreSQL 数据库
确认 `alembic.ini` 中的数据库连接配置:
```ini
sqlalchemy.url = postgresql://用户名:密码@数据库地址:端口/数据库名
```
执行迁移,创建完整表结构:
```bash
alembic upgrade head
```
**Redis**:同上步骤拉取并创建容器。
**Elasticsearch**
拉取 Elasticsearch 8.x 镜像并创建容器,映射端口 `9200`(HTTP API)和 `9300`(集群通信)。首次启动建议关闭安全认证以简化配置:
```bash
docker run -d --name elasticsearch \
-p 9200:9200 -p 9300:9300 \
-e "discovery.type=single-node" \
-e "xpack.security.enabled=false" \
elasticsearch:8.15.0
```
#### 3.3 配置环境变量
```bash
cp env.example .env
```
编辑 `.env` 填写以下核心配置:
```bash
# Neo4j 图数据库
NEO4J_URI=bolt://localhost:7687
NEO4J_USERNAME=neo4j
NEO4J_PASSWORD=your-password
# PostgreSQL 数据库
DB_HOST=127.0.0.1
DB_PORT=5432
DB_USER=postgres
DB_PASSWORD=your-password
DB_NAME=redbear-mem
# 首次启动设为 true,自动迁移数据库
DB_AUTO_UPGRADE=true
# Redis
REDIS_HOST=127.0.0.1
REDIS_PORT=6379
REDIS_DB=1
# Celery
REDIS_DB_CELERY_BROKER=1
REDIS_DB_CELERY_BACKEND=2
# Elasticsearch
ELASTICSEARCH_HOST=127.0.0.1
ELASTICSEARCH_PORT=9200
# JWT 密钥(生成方式:openssl rand -hex 32)
SECRET_KEY=your-secret-key-here
```
#### 3.4 初始化 PostgreSQL 数据库
确认 `alembic.ini` 中的数据库连接配置:
```ini
sqlalchemy.url = postgresql://用户名:密码@数据库地址:端口/数据库名
```
执行迁移,创建完整表结构:
```bash
alembic upgrade head
```
 #### 3.5 启动 API 服务
```bash
uv run -m app.main
```
访问 API 文档:http://localhost:8000/docs
#### 3.5 启动 API 服务
```bash
uv run -m app.main
```
访问 API 文档:http://localhost:8000/docs
 #### 3.6 启动 Celery Worker(可选,用于异步任务)
```bash
# 记忆任务 Worker(线程池,支持高并发 asyncio)
celery -A app.celery_worker.celery_app worker --loglevel=info --pool=threads --concurrency=100 --queues=memory_tasks
# 文档解析 Worker(进程池,CPU 密集型)
celery -A app.celery_worker.celery_app worker --loglevel=info --pool=prefork --concurrency=4 --queues=document_tasks
# 定时任务 Worker(反思引擎等)
celery -A app.celery_worker.celery_app worker --loglevel=info --pool=prefork --concurrency=2 --queues=periodic_tasks
# Beat 调度器
celery -A app.celery_worker.celery_app beat --loglevel=info
```
### 四、前端 Web 应用启动
#### 4.1 安装依赖
```bash
cd web
npm install
```
#### 4.2 修改 API 代理配置
编辑 `web/vite.config.ts`:
```typescript
proxy: {
'/api': {
target: 'http://127.0.0.1:8000', // Windows 用 127.0.0.1,macOS 用 0.0.0.0
changeOrigin: true,
},
}
```
#### 4.3 启动前端服务
```bash
npm run dev
```
#### 3.6 启动 Celery Worker(可选,用于异步任务)
```bash
# 记忆任务 Worker(线程池,支持高并发 asyncio)
celery -A app.celery_worker.celery_app worker --loglevel=info --pool=threads --concurrency=100 --queues=memory_tasks
# 文档解析 Worker(进程池,CPU 密集型)
celery -A app.celery_worker.celery_app worker --loglevel=info --pool=prefork --concurrency=4 --queues=document_tasks
# 定时任务 Worker(反思引擎等)
celery -A app.celery_worker.celery_app worker --loglevel=info --pool=prefork --concurrency=2 --queues=periodic_tasks
# Beat 调度器
celery -A app.celery_worker.celery_app beat --loglevel=info
```
### 四、前端 Web 应用启动
#### 4.1 安装依赖
```bash
cd web
npm install
```
#### 4.2 修改 API 代理配置
编辑 `web/vite.config.ts`:
```typescript
proxy: {
'/api': {
target: 'http://127.0.0.1:8000', // Windows 用 127.0.0.1,macOS 用 0.0.0.0
changeOrigin: true,
},
}
```
#### 4.3 启动前端服务
```bash
npm run dev
```